Elasticsearch是一个高度可伸缩的开源全文搜索和分析引擎,是一个基于Lucene的搜索服务器。它允许你以近实时的方式快速存储、搜索和分析大量的数据。它通常被用作基础的技术来赋予应用程序复杂的搜索特性和需求。
除了先了解es里面的概念外,安装教程也是必不可少的,可以参考此文章哦~
概念
1.NRT
Elasticsearch是一个近实时性(Near Realtime[NRT])的搜索平台。这意味着当你导入一个文档并把它变成可搜索的时间仅会有轻微的延时。
2.cluster
代表一个集群,集群中有多个节点,通过所有的节点一起保存你的全部数据并且提供联合索引和搜索功能的节点集合 ,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。es的一个概念就是去中心化(注意:和区块链中的去中心化意思不同哦),字面上理解就是无中心节点,这是对于集群内部来说的,因为从外部来看es集群,在逻辑上是个整体,你与任何一个节点的通信和与整个es集群通信是等价的。
3.Node 与 Cluster
Elastic 本质上是一个分布式数据库,允许多台服务器协同工作,每台服务器可以运行多个 Elastic 实例。单个 Elastic 实例称为一个节点(node)。一组节点构成一个集群(cluster)。
4.Index
Elastic 会索引所有字段,经过处理后写入一个反向索引(Inverted Index)。查找数据的时候,直接查找该索引。所以,Elastic 数据管理的顶层单位就叫做 Index(索引)。它是单个数据库的同义词。每个 Index (即数据库)的名字必须是小写。
下面的命令可以查看当前节点的所有 Index。
$ curl -X GET 'http://localhost:9200/_cat/indices?v'
5.Document
Index 里面单条的记录称为 Document(文档)。许多条 Document 构成了一个 Index。一个文档是一个可被索引的数据的基础单元。 Document 使用 JSON 格式表示.
6.Type
Document 可以分组,比如weather这个 Index 里面,可以按城市分组(北京和上海),也可以按气候分组(晴天和雨天)。这种分组就叫做 Type,它是虚拟的逻辑分组,用来过滤 Document。
不同的 Type 应该有相似的结构(schema),举例来说,id字段不能在这个组是字符串,在另一个组是数值。这是与关系型数据库的表的一个区别。性质完全不同的数据(比如products和logs)应该存成两个 Index,而不是一个 Index 里面的两个 Type(虽然可以做到)。下面的命令可以列出每个 Index 所包含的 Type。
$ curl 'localhost:9200/_mapping?pretty=true'
根据规划,Elastic 6.x 版只允许每个 Index 包含一个 Type,7.x 版将会彻底移除 Type。
7.shards
代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
分片对于以下两个主要原因很重要:
- 它允许你水平切分你的内容卷
- 它允许你通过分片来分布和并行化执行操作来应对日益增长的执行量
8.replicas
代表索引副本,即复制,es可以设置多个索引的副本,副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
复制对于以下两个主要原因很重要:
- 高可用。它提供了高可用来以防分片或节点宕机。为此,一个非常重要的注意点是绝对不要将一个分片的拷贝放在
跟这个分片相同的机器上。 - 高并发。它允许你的分片可以提供超出自身吞吐量的搜索服务,搜索行为可以在分片所有的拷贝中并行执行。
总结一下,每个索引可以被切分成多个分片,一个索引可以被复制零次(就是没有复制)或多次。一旦被复制,每个索引
将会有一些主分片(就是那些最原始不是被复制出来的分片),还有一些复制分片(就是那些通过复制主分片得到的分
片)。
主分片和复制分片的数量可以在索引被创建时指定。索引被创建后,你可以随时动态修改复制分片的数量,但是不能
修改主分片的数量。
默认情况下,在Elasticsearch中的每个索引被分配5个主分片和一份拷贝,这意味着假设你的集群中至少有两个节点,
你的索引将会有5个主分片和5个复制分片(每个主分片对应一个复制分片,5个复制分片组成一个完整拷贝),总共每个
索引有10个分片。
9.recovery
代表数据恢复或叫数据重新分布,es在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
10.river
代表es的一个数据源,也是其它存储方式(如:数据库)同步数据到es的一个方法。它是以插件方式存在的一个es服务,通过读取river中的数据并把它索引到es中,官方的river有couchDB的,RabbitMQ的,Twitter的,Wikipedia的。
11.gateway
代表es索引快照的存储方式,es默认是先把索引存放到内存中,当内存满了时再持久化到本地硬盘。gateway对索引快照进行存储,当这个es集群关闭再重新启动时就会从gateway中读取索引备份数据。es支持多种类型的gateway,有本地文件系统(默认),分布式文件系统,Hadoop的HDFS和amazon的s3云存储服务。
12.discovery.zen
代表es的自动发现节点机制,es是一个基于p2p的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。
13.Transport
代表es内部节点或集群与客户端的交互方式,默认内部是使用tcp协议进行交互,同时它支持http协议(json格式)、thrift、servlet、memcached、zeroMQ等的传输协议(通过插件方式集成)。
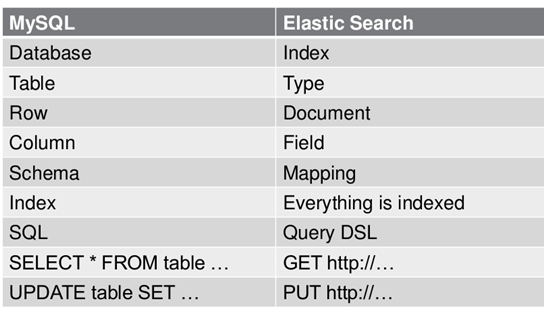
与MySQL对比